
Principi fondamentali della programmazione orientata agli oggetti per creare ottime architetture software.
In questo articolo si introducono i principi fondamentali della programmazione orientata agli oggetti. Questi design principles sono alla base di una buona architettura software object oriented. Per essere un buon programmatore e sopratutto un buon architetto software e creare prodotti manutebili e riusabili, è necessario conoscerli. Su di questi si basano inoltre tutti i Design Patterns.
Per tutti i principi sotto riportati è bene ricordare che è necessario esaminare le proprie necessità e il proprio design per decidere se applicare o meno un certo principio. Ci possono essere casi nei quali si può decidere di non applicare uno di essi perchè non necessario.
Questo è l’elenco dei principi che verranno descritti sotto:
- Encapsulate What Varies
- Single Responsability principles
- Favour composition over inheritance
- Loose coupling
- Program to Interfaces
- Open-Closed Principles
- Liskov’s substitution principle
- Interface segregation principle
- Dependency inversion principle
Encapsulate What Varies
Incapsulare ciò che varia. Uno dei più importanti e il fondamento di molti dei design patterns (Strategy Pattern, Adapter Pattern, Observer Pattern..e molti altri).
Identificare le parti che pensiamo saranno soggette spesso a cambiamenti da quelle che pensiamo non cambieranno e separarle! Separe quello che varia da quello che non varia. In questo modo, quando andremo a modificare o estendere le parti che variano, questo non avrà impatto sulle altre parti.
Single Responsability principle
Il principio di responsabilità singola è molto importante per limitare l’impatto dei cambiamenti in termini di possibilità di introdurre errori e tempi di implementazione. Ogni classe deve avere una singola ragione per cambiare, o meglio una classe deve avere una singola responsabilità. Se infatti assegniamo ad una classe più di una responsabilità è più probabile che in futuro sarà soggetta a cambiamenti.
Supponiamo di avere una classe Appointment che mantiene le informazioni riguardo un appuntamento e in più ha anche un metodo per salvare salvare i dati in un foglio excel. La classe ha due responsabilità, mantenere le informazioni ed esportarle in un excel. Questo viola il principio di singola responsabilità. Se in futuro dovessimo modificare l’esportazione, saremmo costretti ad apportare modifiche al codice della classe, con possibilità di introdurre errori e la necessità di ritestare l’intera classe.
Favour composition over inheritance
Quando si parla di ereditarietà ci si riferisce ad una relazione IS-A, ad esempio un gatto è un (is-a) animale. Quando si parla di composizione invece ci si riferisce ad una relazione HAS-A, ad esempio un automobile ha un (has-a) volante. Favorire la composizione invece di ereditarietà vuol dire quindi favorire relazioni HAS-A rispetto a IS-A. I principali vantaggi di usare la composizione sono:
- Evitare il proliferare di sottoclassi
- Poter modificare a runtime il comportamento di un oggetto
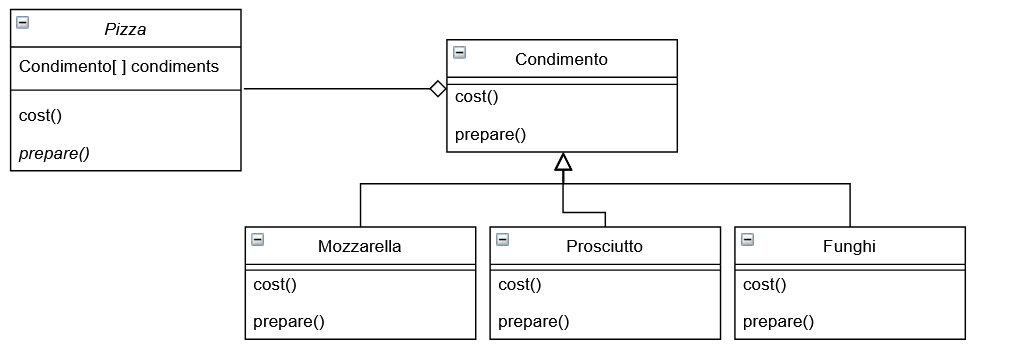
Vediamo un esempio. Supponiamo di avere una classe base Pizza con un metodo Prepare() e un modo Cost(), e le sottoclassi PizzaMargherita, PizzaAlProsciutto, PizzaAiFunghi ognuna delle quale implementa i due metodi.
Se volessimo poi aggiungere al nostro menu la pizza prosciutto+funghi+olive, dovremmo aggiungere una nuova sottoclasse PizzaProsciuttoFunghiOlive per preparare in modo corretto questa pizza e calcolarne il giusto prezzo. E così via dovremmo aggiungere una nuova sottoclasse tutte le volte che vogliamo aggiungere al nostro menu un nuovo tipo di pizza.
Questo porterebbe a moltissime classi e a un codice poco manutenibile.

Perchè non avere invece quindi una classe per ogni condimento ed un’unica classe Pizza, e applicare la relazione HAS-A tra oggetto Pizza e oggetti “condimento”? Una volta creata l’instanza di Pizza possiamo facilmente aggiungere qualsiasi tipo di condimento. Non avremo quindi un proliferare di sottoclassi Pizza per ogni tipo di combinazione, e inoltre potremo comporre la nostra Pizza a runtime e non a compile time.
Loose Coupling
Si parla di loose coupling (accoppiamento “lasco”) tra due componenti quando un componente ha poca conoscenza dell’altro componente. O meglio, quando due componenti non sono dipendenti l’uno dall’altro.
Quando le modifiche ad un componente non comportano modifiche all’altro, o la sostituzione stessa di un componente, senza modificare l’altro, non rompe il funzionamento. Avere un design “loosely coupled” fa si che sia un design “forte” rispetto ai cambiamenti.
Program to Interfaces
Usare tipi astratti al posto di implementazioni concrete per avere un design più flessibile e manutenibile.
Vediamo un esempio.
Supponiamo di avere una classe Calculator che ha una proprietà algorithm che è un’istanza di FastAlgorithm. FastAlgorithm è un’implementazione concreata.

Calculator calculator = new Calculator();
calculator.algorithm = new FastAlgorithm();
In questo modo è deciso a compile time che il tipo dell’algoritmo usato per il nostro oggetto calculator sarà un FastAlgorithm. E se in futuro ne volessi aggiungere un altro? Se volessi non più usare FastAlgorithm ma un altro tipo, oppure poter scegliere a runtime quale usare?
Se usassimo il design mostrato sopra, in questo caso saremmo costretti a modificare molto nel nostro codice, a partire da tutti i riferimenti che potremmo avere a FastAlgorithm.
Quello che possiamo fare, è rivedere il nostro design e pensare per “interfacce”.
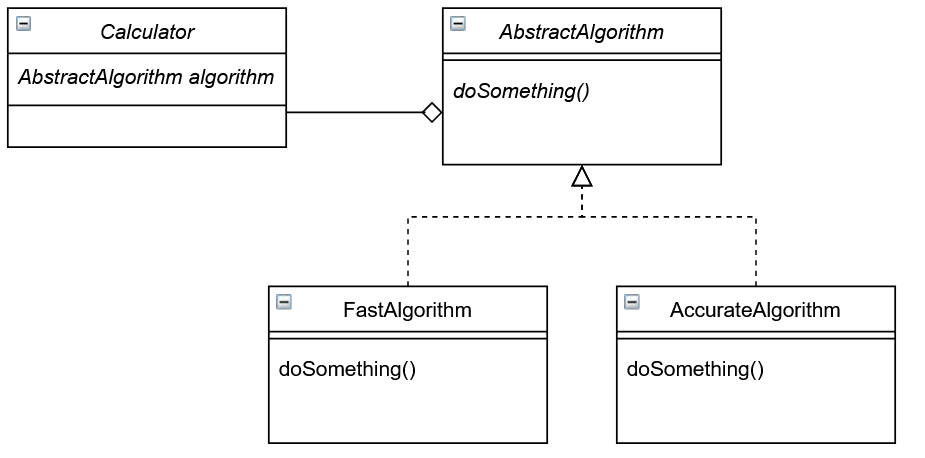
In questa versione abbiamo creato una classe astratta AbstractAlgorithm e la classe Calculator usa il tipo AbstractAlgorithm e non una specifica implementazione. Abbiamo poi due classe concrete FastAlgorithme e AccurateAlgorithm che implementano l’interfaccia AbstractAlgorithm.
A Calculator non importa quale dei due tipi di algoritmo verrà usato, importa solo che questo implementi l’interfaccia di AbstractAlgorithm.
Quindi potremmo avere:
Calculator calculator = new Calculator();
calculator.algorithm = new FastAlgorithm();
OPPURE
calculator.algorithm = new AccurateAlgorithm();Questo design ci permette quindi di poter aggiungere facilmente nuovi algoritmi in futuro, senza dover fare pesanti cambiamenti. E ci permette di scegliere a runtime quale algoritmo usare. Ad esempio potremmo deciderlo sulla base di un’altra variabile.
public void initCalculator(string type)
{
Calculator calculator = new Calculator();
if(type == "fast")
calculator.algorithm = new FastAlgorithm();
else if(type == "accurate")
calculator.algorithm = new AccurateAlgorithm();
}Open-closed principle
Questo principio ci dice che un componente software deve essere aperto ad estensioni ma chiuso alle modifiche. Favorire la composizione rispetto all’ereditarità e pensare per interfacce, sono due principi che di fatto ci aiutano a mantenere una classe aperta ad estensione ma chiusa a modifiche. Pensiamo all’esempio sopra relativo alla class Calculator. Rendendo la proprietà algorithm un tipo astratto abbiamo di fatto reso la classe aperta ad estensioni e chiusa a modifiche. Potremmo infatti estendere il funzionamento di Calculator andando ad implementare nuovi classi concrete che implementano l’interfaccia AbstractAlgorithm. Calculator è inoltre chiusa a modifiche, poiché non sarà necessario modificarla per poter modificare l’algoritmo usato dalla classe.
Liskov’s substitution principle
Il principio di sostituzione di Liskov’s ci dice che una sottoclasse deve poter sempre essere sostituita dalla classe base.
Capiamo meglio con un classico esempio.
Supponiamo di avere una classe Rectangle.
Nella classe Rectangle abbiamo due variabili per memorizzare base (width) e altezza (height), dei metodi per impostare e rileggere le due variabili width e height (setWidth(), getWidth(), setHeight(), getHeight()) , e un metodo per calcolare l’area.
Supponiamo ora di voler creare una classe Square che rappresenti un quadrato. Se ci poniamo la domanda, “un quadrato è un (IS-A) rettangolo?” la risposta è sì. E quindi ci verrebbe naturale creare una classe Square, sottoclasse della classe Rectangle.
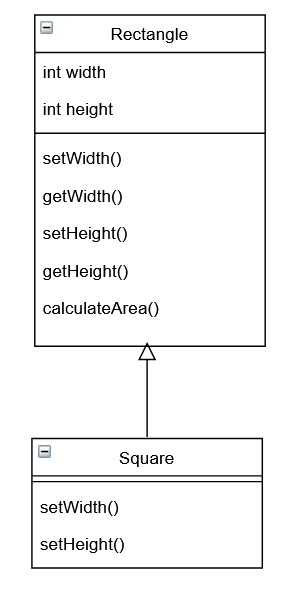
Però per essere sicuri che la classe Square abbia sempre il comportamento desiderato, ovvero rappresentare un quadrato, vogliamo essere sicuri che base e altezza siano sempre uguali.
Quindi andiamo a reimplementare i metodi setHeight() e setWidth() in modo che in entrambi vengano impostate entrambe le variabili. In questo modo avranno sempre lo stesso valore.
public void Square::setWidth(int value)
{
width = value;
height = value;
}
public void Square::setHeight(int value)
{
width = value;
height = value;
}Facendo così ci siamo assicurati che la nostra classe Square rappresenti sempre un quadrato. Ma abbiamo rispettato il principio di Liskov? La risposta è NO. E questo può portare a comportamenti inattesi nel codice quando si vuole utilizzare il tipo Rectangle al posto di Square.
Facciamo un esempio. Ipotizziamo di voler creare un funzione di test per verificare che la funzione calculateArea() funzioni correttamente.
public void testCalculateArea(Rectangle r, int w, int h)
{
r.setWidth(w);
r.setHeight(h);
if((w * h) != r.calculateArea())
System.out.Println("Failed!");
else
System.out.Println("Pass!");
}Ma cosa succede quando andiamo a testare?
Rectangle rect = new Rectangle();
Rectangle square = new Square();
tester.testCalculateArea(rect, 5, 5); // PASS!
tester.testCalculateArea(rect, 5, 4); // PASS!
tester.testCalculateArea(square, 5, 5); // PASS!
tester.testCalculateArea(square, 5, 4); // FAIL!
Quando la width e la height passate sono diverse, il test con square fallisce! Infatti la chiamata r.setHeight(h); in questo caso va ad impostare anche la width al valore 4 e il controllo if((w * h) != r.calculateArea()) ritorna true!
Il principio di sostituzione di Liskov ci spinge quindi a riflettere maggiormente quando andiamo a creare una classe ereditando da un’altra. La risposta alla domanda “un quadrato è un rettangolo” è sì, ma come abbiamo visto non è l’unica domanda che dobbiamo porci. Importante è anche verificare che la sottoclasse sia sostituibile con la classe base senza alterare la correttezza del programma. Per fare questo è bene tener conto non sono delle proprietà che ha una classe, ma del comportamento: un quadrato e un rettangolo hanno stesse proprietà, ma comportamenti diversi!
Interface segregation principle
Questo principio ci dice che le classi non dovrebbero essere forzate a dipendere da metodi che non usano.
Facciamo un esempio.
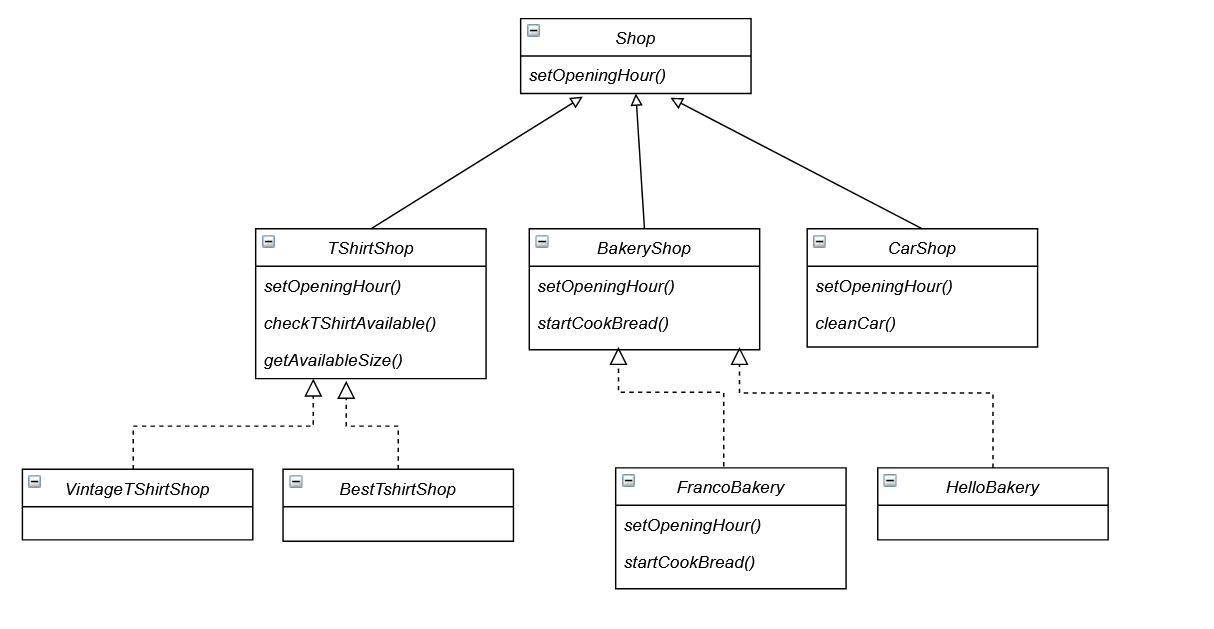
Ipotizziamo di avere create un’interfaccia per rappresentare un negozio, Shop. Come abbiamo già capito dai principi precedenti, pensare a partire da interfacce è ciò che ci permette la flessibilità. E ipotizziamo che inizialmente il nostro software debba gestire solo negozi di t-shirt, TShirtShop. Avremo ad esempio metodi come setOpeningHour() , per impostare l’orario di apertura, checkTShirtAvailable(), per verificare se una t-shirt è disponibe, getAvailableSize(), per avere le taglie disponibili.
A questo punto vogliamo gestire un altro tipo di Shop, che non prevede la vendita di t-shirt o il controllo delle taglie disponibili. Ad esempio un fornaio, BakeryShop, che potrebbe necessitare del metodo startCookBread(), per iniziare a cucinare il pane. Poi dovremo gestire negozi che vendono automobili usate, a cui servirà il metodo cleanCar(). Via via quindi dovremo aggiungere metodi alla nostra interfaccia.
Quando andremo ad implementare le classi concrete per i tre tipi di negozi, ci troveremo a dover implementare per queste classi dei metodi che non verranno mai usati!

class BakeryShop: public Shape {
public:
void setOpeningHour() {
// Codice per impostare l'orario
}
void startCookingBread() {
// Codice per iniziare a cuocere il pane
}
// I 3 METODI SOTTO CI DEVONO ESSERE PER IMPLEMENTARE L'INTERFACCIA, MA NON FANNO NULLA!!
void checkTShirAvailable() { }
void getAvailableSize() { }
void cleanCar() { }
};Come possiamo fare quindi per evitare questo e mantenere la flessibilità che ci garantisce l’uso delle interfacce? Quello che possiamo fare è avere sì la classe astratta Shop, ma da questa derivare altre 3 classi astratte, una per ogni tipo di negozio. Nella classe astratta Shop lasceremo solo i metodi comuni a tutti gli shop (setOpeningHour()), mentre i metodi specifici per ogni tipo di shop, saranno indicati nella specifica classe astratta. A questo punto l’implementazione concreta di un negozio di tipo BakeryShop, la classe FrancoShop ad esempio, potrà effettivamente implementare solo il metodo cookingBread().
Dependency Inversion principle
Questo principio ci indica che i moduli di alto livello non dovrebbero dipendere da moduli di più basso livello.
Solitamente siamo abituati a pensare andando a decomporre un problema con un approccio top-down. Partiamo da un problema, e lo decomponiamo in componenti di alto livello che dipendono da altri componenti di basso livello. Questo però rende strettamente legati i componenti di alto livello a quelli di basso livello.
Spesso in questo modo risulta poi difficile poter riusare i componenti di alto livello, magari in un altro progetto, con un’implementazione completamente diversa dei componenti di basso livello. Tutto questo è da evitare.
Questo principio ci indica che:
- I componenti di alto livello non dovrebbero dipendere da quelli di basso livello. Ma entrambi dovrebbero dipendere da astrazioni.
- Le astrazioni non dovrebbero dipende da dettagli, ma viceversa. I dettagli dovrebbero dipendere dalle astrazioni.
Vediamo di chiarire con un esempio.
Supponiamo di voler creare una classe che rappresenta un controllo remoto per aprire/chiudere una finestra.

RemoteControl ha come membro l’istanza w della classe Window. Nel metodo click() vengono chiamate le funzioni w.openWindow() e w.closeWindow()
Ma se volessimo usare la stessa classe RemoteControl per gestire altri tipoi di dispositivi, ad esempio l’apertura di una porta? In questa implementazione RemoteControl è fortemente legato al componente Window, quindi non stiamo rispettando quanto ci dice questo principio.
Vediamo come modificare il design.
Il principio ci dice che i componenti di alto livello non devono dipendere da componenti di basso livello ma da astrazioni. Creiamo quindi una generica interfaccia che rappresenta un generico dispositivo, Device. E modifichiamo RemoteControl in modo che abbia come membro non più un’implementazione concreta, ma un generico Device.
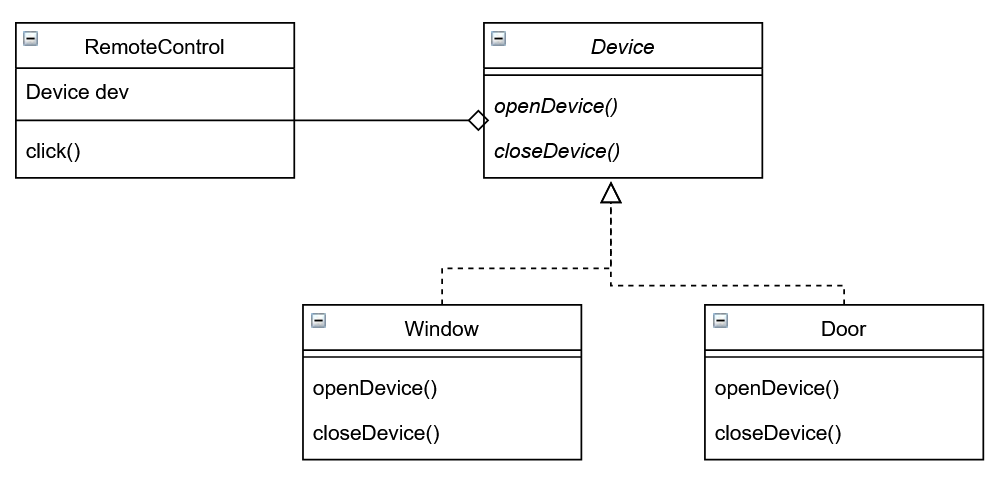
I componenti di cui vogliamo quindi controllare l’apertura/chiusura con il nostro RemoteControl, saranno implementazioni concrete di Device.
Il principio ci dice anche che le astrazioni non dovrebbero dipendere da dettagli. E in fatti in questo caso Device implementa due metodi generici openDevice() e closeDevice(), che saranno poi implementati dalle classi concrete e andranno a chiamare i metodi specifici.
void Window::openDevice()
{
this.openWindow();
}
void Windows::closeDevice()
{
this.closeWindows();
}